
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 백로과
- SimpleCraft
- django
- 계수정렬
- 가마우지과
- ADsP
- structured_array
- keras
- 맑은소리 스피치학원
- Birthday paradox
- AI전략게임
- 오리과
- 딥러닝공부
- 비둘기목
- 딱다구리과
- 흰날개해오라기
- 생일문제
- 솔딱새과
- 기러기목
- 참새목
- IBK기업은행 인턴
- 한국의 새
- 딥러닝 공부
- Python
- python3
- 참새과
- 직박구리과
- 비둘기과
- AI역량평가
- 한국의새
- Today
- Total
진박사의 일상
[데베시] 8장 - SQL 본문
SQL 기본 컨셉
SQL 소개
- IBM Research 개발, 특수 목적의 declarative programming language(선언적 프로그래밍 언어)
- ANSI에서 표준화된 현재 가장 보편적인 DBMS 언어
- 구성
- DDL(Data Definition Language) : DB, Tables, Index에 대한 명령어, create, modify, delete
- DML(Data Manipulation Languate) : Tuple에 대한 명령어, Retrieval, insert, modify, delete
Schema Creation
- SQL schema : table & constructs의 집합 -> 같은 DB application에 속함
- CREATE SCHEMA statement로 생성
ex) Jsmith 소유의 COMPANY Schema 생성 : CREATE SCHEMA COMPANY AUTHORIZATION 'Jsmith';
Table Creation
- CREATE TABLE statement : table name과 Attribute의 list, 초기 constraints로 구성
- Attributes
- Data types : INT, FLOAT, DECIMAL, CHAR(n), VARCHAR(n) ...
- NOT NULL attribute constraint : NULL이 허용되지 않은 attribute
- DEFAULT clause : NULL 값으로 들어오는 것을 DEFALT 값으로 대치
- Initial constraints
- PRIMARY KEY clause : 어떤 1개 또는 그 이상의 attribute가 해당 relation의 primary key인지를 정함
- UNIQUE clause : 후보키(alternate keys)를 명시
- FOREIGN KEY clause : referential integrity constraint를 위한 외래키(foreign key)를 명시. referential triggered action(참조무결성이 위배될 때 취하는 행동)을 정할 수 있음.
- Actions : SET NULL(null로 치환), CASCADE(참조값이 변할 때 같이 변동), SET DEFAULT(default로 치환) / Triggers : ON DELETE(참조 relation이 삭제될 때), ON UPDATE(참조 relation이 update될 때)
ex) DEPARTMENT table을 생성하는 Query
CREATE TABLE DEPARTMENT
(Dname VARCHAR(10) NOT NULL,
Dnumber INT NOT NULL,
Mgr_ssn CHAR(9) NOT NULL,
Mgr_start_date DATE,
PRIMARY KEY (Dnumber),
UNIQUE (Dname),
FOREIGN KEY (Mgr_ssn) REFERENCES EMPLOYEE(Ssn) ); -> 아직 EMPLOYEE를 선언하지 않았다면 문제 생김
ex2) EMPLOYEE TABLE 생성 (DECIMAL(10,2) -> 10자리 중 2자리까지 소수점이 될 수 있는 숫자 타입)



Referential treggered actions
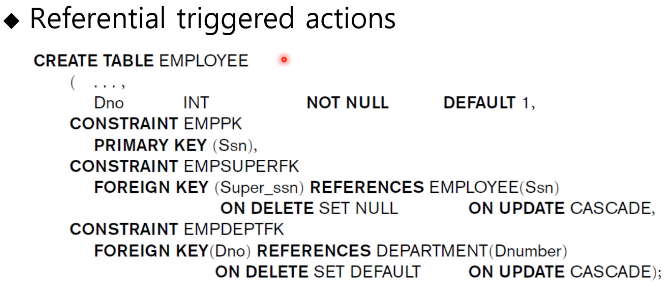
CONSTRAINT statement -> Constraint의 이름을 정의
CONSTRAINT EMPSUPERFK에서
ON DELETE SET NULL -> 상사가 그만두면 NULL로
ON UPDATE CASECADE -> 상사의 Ssn의 값이 변동이 된다면 연동해서 바꾸라
CONSTRAINT EMPDEPTFK
ON DELETE SET DEFAULT -> 부서가 사라지면 DEFAULT값인 1로 변경
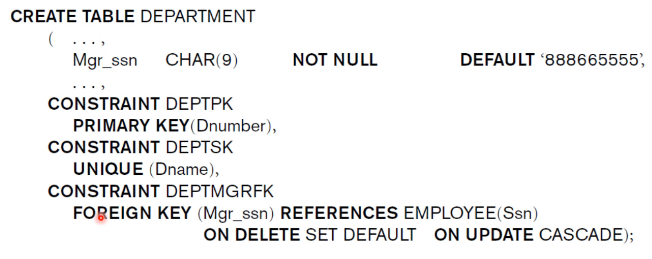

ON DELETE CASCADE -> 만약 참조하던 것이 삭제되면 같이 삭제되어라
DROP SCHEMA statement
- 모든 schema가 더이상 필요 없을 때 삭제
- option : CASCADE(schema와 모든 element 다 제거), RESTRICT(schema에 다른 어떤 element도 남아있지 않을 때만 제거 가능)
ex) DROP SCHEMA COMPANY CASCADE;
DROP TABLE statement
- table definition과 해당하는 모든 tuple을 제거
- option : CASCADE(table과 table을 참조하고 있는 모든 element를 제거), RESTRICT(아무런 제약조건에도 참조되지 않는 테이블의 경우만 제거 가능)
ex) DROP TABLE DEPENDENT CASCADE;
ALTER TABLE statement
- table의 구조를 변경 ex) column을 추가 or 삭제, column의 정의를 변경, constriant를 추가하거나 삭제

ALTER TABLE ~ ADD COLUMN : column 추가
ALTER TABLE ~ DROP COLUMN ~ CASCADE : COLUMN 삭제 CASCADE식으로
ALTER TABLE ~ ALTER COLUMN ~ DROP DEFAULT / SET DEFAULT ~ : DEFAULT 값을 삭제하거나 추가
ALTER TABLE ~ DROP CONSTRAINT : CONSTRAINT 제거
~여기까지 DDL~
8장- 2
~여기부터 DML~
SELECT Query Basics
- SELECT statement : DB로부터 원하는 정보를 가져오는 문 (관계대수의 select와는 다름 -> 관계대수의 select, project, join을 모두 합친 연산)
- ※SQL은 완전히 똑같은 속성값을 가진 2 이상의 tuple의 존재를 허용(relational model과 다르게, 즉 Set이 아님.) -> 중복을 원하지 않는다면 DISTINCT clause를 이용 가능.
- base form : SELECT <attribute list> FROM <table list> WHERE <condition>;
ex) 이름이 'Jothn. B. Smith'인 employee의 생일과 주소를 찾아라 ->
SELECT Bdate, Address
FROM EMPLOYEE
WHERE Fname='John' AND Minit='B' AND Lname='Smith';
Q1. Research 부서의 모든 직원의 이름과 주소를 검색하시오 ->
SELECT Fname, Lname, Address
FROM EMPLOYEE, DEPARTMENT
WHERE Dname='Reasearch' AND Dnumber=Dno;
Q2. 'Stafford'에 위치한 모든 Project에 대해 프로젝트 number, 관장하는 부서 number, 관장 부서의 매니저의 last name, 주소, 생년월일을 출력하시오 ->
SELECT Pnumber, Dnumber, Lname, Address, Bdate
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Plocation='Stafford' AND Dnum=Dnumber AND Mgr_ssn=Ssn;
모호한 Attribute names
- 같은 table(relations) 내에서는 같은 이름 불가능 -> but 다른 table끼리는 가능.
-> 이러한 모호성을 없애기 위해 relation name과 붙여서 표시
ex) EMPLOYEE와 DEPARTMENT에 둘다 Name과 Dnumber라는 동일한 Attribute가 있다고 하면 Q1은 다음처럼
SELECT Fname, EMPLOYEE.Name, Address
FROM EMPLOYEE, DEPARTMENT
WHERE DEPARTMENT.Name='Reasearch' AND DEPARTMENT.Dnumber=EMPLOYEE.Dnumber;
Table Aliases (AS) - 별명 짓기
Q3. 모든 사원에 대해 사원의 Fname과 Lname 그리고 그 사원의 상사의 Fname과 Lname을 출력하시오. ->
SELECT E.Fname, E.Lname, S.Fname, S.Lname
FROM EMPLOYEE AS E, EMPLOYEE AS S
WHERE E.Super_ssn = S.Ssn;
- AS는 Attribute의 별명도 지을 수 있다. ex) EMPLOYEE AS E(FN, MI, LN, SSN, BD, ADDR, SEX, SAL, SSSN, DNO)
Missing WHERE Clause
- condition이 없는 tuple selection, 만약 FROM이 2개 이상의 relation이라면 해당 relatino의 CROSS PRODUCT를 출력
ex) SELECT Ssn FROM EMPLOYEE; -> 모든 직원의 number를 출력
Use of the Asterisk(*)
- * 는 모든 Attribute이라는 의미.
Tables as Sets
- SQL은 자동적으로 중복을 제거하지 않음 -> 일부 경우에 사용되므로 -> 만약 중복이 제거될 필요가 있다면? -> DISTINCT keyword를 사용 <-> 반대는 ALL(default)
- Set operations : UNION, EXCEPT(difference), INTERSECT -> 이런 Query는 자동으로 중복 제거
Q4. last name이 Smith인 사람이 직원으로 참여하는 프로젝트이면서 프로젝트의 담당 부서의 매니저로서 참가하는 모든 프로젝트의 번호를 출력하시오.
(SELECT DISTINCT Pnumber
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Dnum=Dnumber AND Mgr_ssn=SSn AND Lname='Smith')
UNION
(SELECT DISTINCT Pnumber
FROM PROJECT, WORKS_ON, EMPLOYEE
WHERE Pnumber=Pno AND Essn=SSn AND Lname='Smith');
-> 앞쪽은 매니저로 참가하는 경우의 SELECT, 뒤쪽은 직원으로 참가하는 경우의 SELECT -> 두 경우 모두 해당해야 하므로 교집합(UNION)으로 합쳐줌
'프로그래밍 > 공부' 카테고리의 다른 글
| [데베시] 9장 복잡한 SQL (0) | 2021.11.20 |
|---|---|
| [컴보] 10장 - Buffer Overflow (0) | 2021.11.15 |
| [컴보] 8장 IDS (0) | 2021.11.03 |
| [컴보] 7장 DoS (0) | 2021.11.01 |
| [데베시] 7강 - Relational Algebra (0) | 2021.10.25 |


